pip版本有可能太旧,此时只需要更新一下pip就好 (命令行中输入更新代码:python -m pip install --upgrade pip)2、Scrapy框架的基础知识2.1 基本组成:spiders为核心代码,主要是一些爬虫的...
”python scrapy爬虫框架“ 的搜索结果
Scrapy是用Python实现一个为爬取网站数据、提取结构性数据而编写的应用框架。 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...

本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...

Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。:它负责处理所有Responses,从中分析提取数据,...
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。提示:Twisted 是一个基于事件驱动的网络引擎框架,同样...
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到...
本项目是基于Python的Scrapy爬虫框架设计源码,包含22个文件,其中主要包含12个py源代码文件,4个xml配置文件等。系统采用了Python编程语言,实现了网站爬虫的功能,可以高效地抓取网站数据。项目结构清晰,代码...
爬取网页上的信息 import time from selenium import webdriver path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe" driver = webdriver.Chrome(executable_path=path) ...
Python Scrapy 爬虫框架整个学习demo,包括后端数据库等逻辑的一些代码
以上我们以一个实战项目为依托,将建立 Scrapy 项目的过程从零开始,深入浅出,让读者能够实践爬虫的整个过程。
注意事项:scrapy和twisted存在兼容性问题,如果安装twisted版本过高,运行scrapy startproject project_name的时候会提示报错,安装twisted==13.1.0即可。
在本文内容里小编给大家分享的是关于windows下搭建python scrapy爬虫框架的教学内容,需要的朋友们学习下。
本源码提供了一个基于Python的Scrapy爬虫框架设计。项目包含20个文件,其中包括6个Python字节码文件、6个Python源文件、3个XML文件、1个Gitignore文件、1个IML文件、1个CSV文件、1个TXT文件和1个CFG文件。这个项目是...
Scrapy 是用 Python 实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定...
本系统采用Scrapy爬虫框架来开发,使用Xpath网页提取技术对下载网页进行内容解析,使用Redis做分布式,使用MongoDB对提取的数据进行存储,使用Django开发可视化界面对爬取的结果进行友好展示,设计并实现了针对链家...
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,...
在使用Scrapy时,请务必遵守相关法律法规和爬虫协议,以确保你的爬虫任务是合法和合规的。要创建一个管道,你需要在项目文件夹中创建一个名为“pipelines.py”的文件,并在其中定义你的管道类。要创建一个中间件,你...
Python Scrapy爬虫框架安装和创建
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
建议使用python 2.7版本,个人使用python2.7.8版本 32位系统,安装没有出现任何问题
Scrapy是一个功能强大并且非常快速的网络爬虫框架,是非常优秀的python第三方库,也是基于python实现网络爬虫的重要的技术路线。 Scrapy的安装: 直接在命令提示符窗口执行pip install scrapy貌似不行。 我们需要先...
大家好我是小菜鸡,让我们一起学习Python的网络爬虫框架-Scrapy爬虫框架的使用(一起努力,咱们顶峰相见!!!)
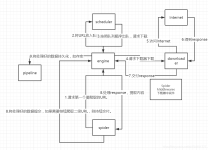
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
Python Scrapy爬虫框架实战应用 通过上一节《Python Scrapy爬虫框架详解》的学习,您已经对 Scrapy 框架有了一个初步的认识,比如它的组件构成,配置文件,以及工作流程。本节将通过一个的简单爬虫项目对 Scrapy ...
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。...
推荐文章
- 记录nvm use node.js版本失败,出现报错: exit status 1: ��û���㹻��Ȩ��ִ�д˲�����_nvm use失败-程序员宅基地
- lua面向对象编程之点号与冒号的差异详细比较-程序员宅基地
- 百度云虚假下载_虚假新闻:关于公共云的5种常见误解-程序员宅基地
- Tesseract图像识别OCR的学习1_tesseract doocr-程序员宅基地
- 不同层级的Android开发者的不同行为,我们该如何进阶和规划?-程序员宅基地
- Pelee: A real-time object detection system on mobile devices-程序员宅基地
- Hadoop环境搭建(保姆级教学)_hadoop平台搭建步骤-程序员宅基地
- ZooKeeper实战之ZkClient客户端实现负载均衡_zookeeper实现负载均衡案例-程序员宅基地
- Android 枚举 VS 枚举注解_android 枚举注解-程序员宅基地
- HDU1715--第i个斐波那契数 大菲波数_返回第i个斐波那契数-程序员宅基地